Freexian Collaborators: Debian Contributions: Freexian meetup, debusine updates, lpr/lpd in Debian, and more! (by Utkarsh Gupta, Stefano Rivera)
 Contributing to Debian
is part of Freexian s mission. This article
covers the latest achievements of Freexian and their collaborators. All of this
is made possible by organizations subscribing to our
Long Term Support contracts and
consulting services.
Contributing to Debian
is part of Freexian s mission. This article
covers the latest achievements of Freexian and their collaborators. All of this
is made possible by organizations subscribing to our
Long Term Support contracts and
consulting services.
Freexian Meetup, by Stefano Rivera, Utkarsh Gupta, et al.
During DebConf, Freexian organized a
meetup for its
collaborators and those interested in learning more about Freexian and its
services. It was well received and many people interested in Freexian showed up.
Some developers who were interested in contributing to LTS came to get more
details about joining the project. And some prospective customers came to get to
know us and ask questions.
Sadly, the tragic loss of Abraham
shook DebConf, both individually and structurally. The meetup got rescheduled to
a small room without video coverage. With that, we still had a wholesome
interaction and here s a quick picture from the meetup taken by Utkarsh (which
is also why he s missing!).

Debusine, by Rapha l Hertzog, et al.
Freexian has been investing into
debusine for a while, but
development speed is about to increase dramatically thanks to funding from
SovereignTechFund.de. Rapha l laid out the
5 milestones of
the funding contract, and filed the
issues for the first milestone.
Together with Enrico and Stefano, they established a
workflow
for the expanded team.
Among the first steps of this milestone, Enrico started to work on a
developer-friendly description of debusine
that we can use when we reach out to the many Debian contributors that we will
have to interact with. And Rapha l started the design work of the autopkgtest
and lintian tasks,
i.e. what s the interface to schedule such tasks, what behavior and what
associated options do we support?
At this point you might wonder what debusine is supposed to be let us try to
answer this: Debusine manages scheduling and distribution of Debian-related
build and QA tasks to a network of worker machines. It also manages the
resulting artifacts and provides the results in an easy to consume way.
We want to make it easy for Debian contributors to leverage all the great QA
tools that Debian provides. We want to build the next generation of Debian s
build infrastructure, one that will continue to reliably do what it already
does, but that will also enable distribution-wide experiments, custom package
repositories and custom workflows with advanced package reviews.
If this all sounds interesting to you, don t hesitate to
watch the project on salsa.debian.org
and to contribute.
lpr/lpd in Debian, by Thorsten Alteholz
During Debconf23, Till Kamppeter presented CPDB (Common Print Dialog Backend),
a new way to handle print queues. After this talk it was discussed whether the
old lpr/lpd based printing system could be abandoned in Debian or whether there
is still demand for it.
So Thorsten asked on the
debian-devel email list
whether anybody uses it. Oddly enough, these old packages are still useful:
- Within a small network it is easier to distribute a printcap file, than to
properly configure cups clients.
- One of the biggest manufacturers of WLAN router and DSL boxes only supports
raw queues when attaching an USB printer to their hardware. Admittedly the
CPDB still has problems with such raw queues.
- The Pharos printing system at MIT is still lpd-based.
As a result, the lpr/lpd stuff is not yet ready to be abandoned and Thorsten
will adopt the relevant packages (or rather move them under the umbrella of the
debian-printing team). Though it is not planned to develop new features, those
packages should at least have a maintainer. This month Thorsten adopted rlpr,
an utility for lpd printing without using /etc/printcap. The next one he is
working on is lprng, a lpr/lpd printer spooling system. If you know of any
other package that is also needed and still maintained by the QA team, please
tell Thorsten.
/usr-merge, by Helmut Grohne
Discussion about lifting the file move moratorium has been initiated with the
CTTE and the release team. A formal lift is
dependent on updating debootstrap in older suites though. A significant number
of packages can automatically move their systemd unit files if
dh_installsystemd and systemd.pc change their installation targets.
Unfortunately, doing so makes some packages FTBFS and therefore
patches have been filed.
The analysis tool, dumat, has been enhanced to better understand
which upgrade scenarios are considered supported
to reduce false positive bug filings and gained a mode for
local operation on a .changes file
meant for inclusion in salsa-ci. The filing of bugs from dumat is still
manual to improve the quality of reports.
Since September, the moratorium
has been lifted.
Miscellaneous contributions
- Rapha l updated Django s backport in bullseye-backports to match the latest
security release that was published in bookworm. Tracker.debian.org is still
using that backport.
- Helmut Grohne sent 13 patches for cross build failures.
- Helmut Grohne performed a maintenance upload of
debvm enabling its
use in autopkgtests.
- Helmut Grohne wrote an API-compatible reimplementation of
autopkgtest-build-qemu. It is powered by mmdebstrap, therefore
unprivileged, EFI-only and will soon be
included in mmdebstrap.
- Santiago continued the work regarding how to make it easier to
(automatically) test reverse dependencies.
An example
of the ongoing work was presented during the Salsa CI BoF at DebConf 23.
In fact, omniorb-dfsg test pipelines as the above were used for the
omniorb-dfsg 4.3.0 transition,
verifying how the reverse dependencies (tango, pytango and omnievents) were
built and how their autopkgtest jobs run with the to-be-uploaded omniorb-dfsg
new release.
- Utkarsh and Stefano attended and helped run DebConf 23. Also continued
winding up DebConf 22 accounting.
- Anton Gladky did
some science team uploads
to fix RC bugs.
lpr/lpd in Debian, by Thorsten Alteholz
During Debconf23, Till Kamppeter presented CPDB (Common Print Dialog Backend),
a new way to handle print queues. After this talk it was discussed whether the
old lpr/lpd based printing system could be abandoned in Debian or whether there
is still demand for it.
So Thorsten asked on the
debian-devel email list
whether anybody uses it. Oddly enough, these old packages are still useful:
- Within a small network it is easier to distribute a printcap file, than to
properly configure cups clients.
- One of the biggest manufacturers of WLAN router and DSL boxes only supports
raw queues when attaching an USB printer to their hardware. Admittedly the
CPDB still has problems with such raw queues.
- The Pharos printing system at MIT is still lpd-based.
As a result, the lpr/lpd stuff is not yet ready to be abandoned and Thorsten
will adopt the relevant packages (or rather move them under the umbrella of the
debian-printing team). Though it is not planned to develop new features, those
packages should at least have a maintainer. This month Thorsten adopted rlpr,
an utility for lpd printing without using /etc/printcap. The next one he is
working on is lprng, a lpr/lpd printer spooling system. If you know of any
other package that is also needed and still maintained by the QA team, please
tell Thorsten.
/usr-merge, by Helmut Grohne
Discussion about lifting the file move moratorium has been initiated with the
CTTE and the release team. A formal lift is
dependent on updating debootstrap in older suites though. A significant number
of packages can automatically move their systemd unit files if
dh_installsystemd and systemd.pc change their installation targets.
Unfortunately, doing so makes some packages FTBFS and therefore
patches have been filed.
The analysis tool, dumat, has been enhanced to better understand
which upgrade scenarios are considered supported
to reduce false positive bug filings and gained a mode for
local operation on a .changes file
meant for inclusion in salsa-ci. The filing of bugs from dumat is still
manual to improve the quality of reports.
Since September, the moratorium
has been lifted.
Miscellaneous contributions
- Rapha l updated Django s backport in bullseye-backports to match the latest
security release that was published in bookworm. Tracker.debian.org is still
using that backport.
- Helmut Grohne sent 13 patches for cross build failures.
- Helmut Grohne performed a maintenance upload of
debvm enabling its
use in autopkgtests.
- Helmut Grohne wrote an API-compatible reimplementation of
autopkgtest-build-qemu. It is powered by mmdebstrap, therefore
unprivileged, EFI-only and will soon be
included in mmdebstrap.
- Santiago continued the work regarding how to make it easier to
(automatically) test reverse dependencies.
An example
of the ongoing work was presented during the Salsa CI BoF at DebConf 23.
In fact, omniorb-dfsg test pipelines as the above were used for the
omniorb-dfsg 4.3.0 transition,
verifying how the reverse dependencies (tango, pytango and omnievents) were
built and how their autopkgtest jobs run with the to-be-uploaded omniorb-dfsg
new release.
- Utkarsh and Stefano attended and helped run DebConf 23. Also continued
winding up DebConf 22 accounting.
- Anton Gladky did
some science team uploads
to fix RC bugs.
systemd unit files if
dh_installsystemd and systemd.pc change their installation targets.
Unfortunately, doing so makes some packages FTBFS and therefore
patches have been filed.
The analysis tool, dumat, has been enhanced to better understand
which upgrade scenarios are considered supported
to reduce false positive bug filings and gained a mode for
local operation on a .changes file
meant for inclusion in salsa-ci. The filing of bugs from dumat is still
manual to improve the quality of reports.
Since September, the moratorium
has been lifted.
Miscellaneous contributions
- Rapha l updated Django s backport in bullseye-backports to match the latest
security release that was published in bookworm. Tracker.debian.org is still
using that backport.
- Helmut Grohne sent 13 patches for cross build failures.
- Helmut Grohne performed a maintenance upload of
debvm enabling its
use in autopkgtests.
- Helmut Grohne wrote an API-compatible reimplementation of
autopkgtest-build-qemu. It is powered by mmdebstrap, therefore
unprivileged, EFI-only and will soon be
included in mmdebstrap.
- Santiago continued the work regarding how to make it easier to
(automatically) test reverse dependencies.
An example
of the ongoing work was presented during the Salsa CI BoF at DebConf 23.
In fact, omniorb-dfsg test pipelines as the above were used for the
omniorb-dfsg 4.3.0 transition,
verifying how the reverse dependencies (tango, pytango and omnievents) were
built and how their autopkgtest jobs run with the to-be-uploaded omniorb-dfsg
new release.
- Utkarsh and Stefano attended and helped run DebConf 23. Also continued
winding up DebConf 22 accounting.
- Anton Gladky did
some science team uploads
to fix RC bugs.
debvm enabling its
use in autopkgtests.autopkgtest-build-qemu. It is powered by mmdebstrap, therefore
unprivileged, EFI-only and will soon be
included in mmdebstrap.In fact, omniorb-dfsg test pipelines as the above were used for the omniorb-dfsg 4.3.0 transition, verifying how the reverse dependencies (tango, pytango and omnievents) were built and how their autopkgtest jobs run with the to-be-uploaded omniorb-dfsg new release.
 Debian Celebrates 30 years!
We celebrated our
Debian Celebrates 30 years!
We celebrated our 






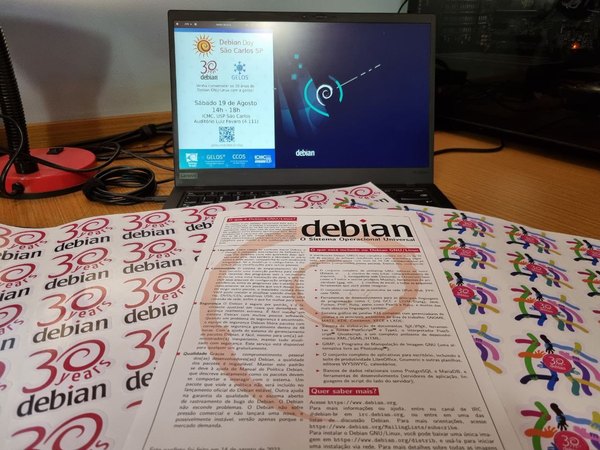

















 This year's Debian day was a pretty special one, we are celebrating 30 years!
Giving the importance of this event, the Brazilian community planned a very
special week. Instead of only local gatherings, we had a week of online talks
streamed via Debian Brazil's youtube channel (soon the recordings will be
uploaded to Debian's peertube instance). Nonetheless the local celebrations
happened around the country and I've organized one in S o Carlos with the help
of
This year's Debian day was a pretty special one, we are celebrating 30 years!
Giving the importance of this event, the Brazilian community planned a very
special week. Instead of only local gatherings, we had a week of online talks
streamed via Debian Brazil's youtube channel (soon the recordings will be
uploaded to Debian's peertube instance). Nonetheless the local celebrations
happened around the country and I've organized one in S o Carlos with the help
of 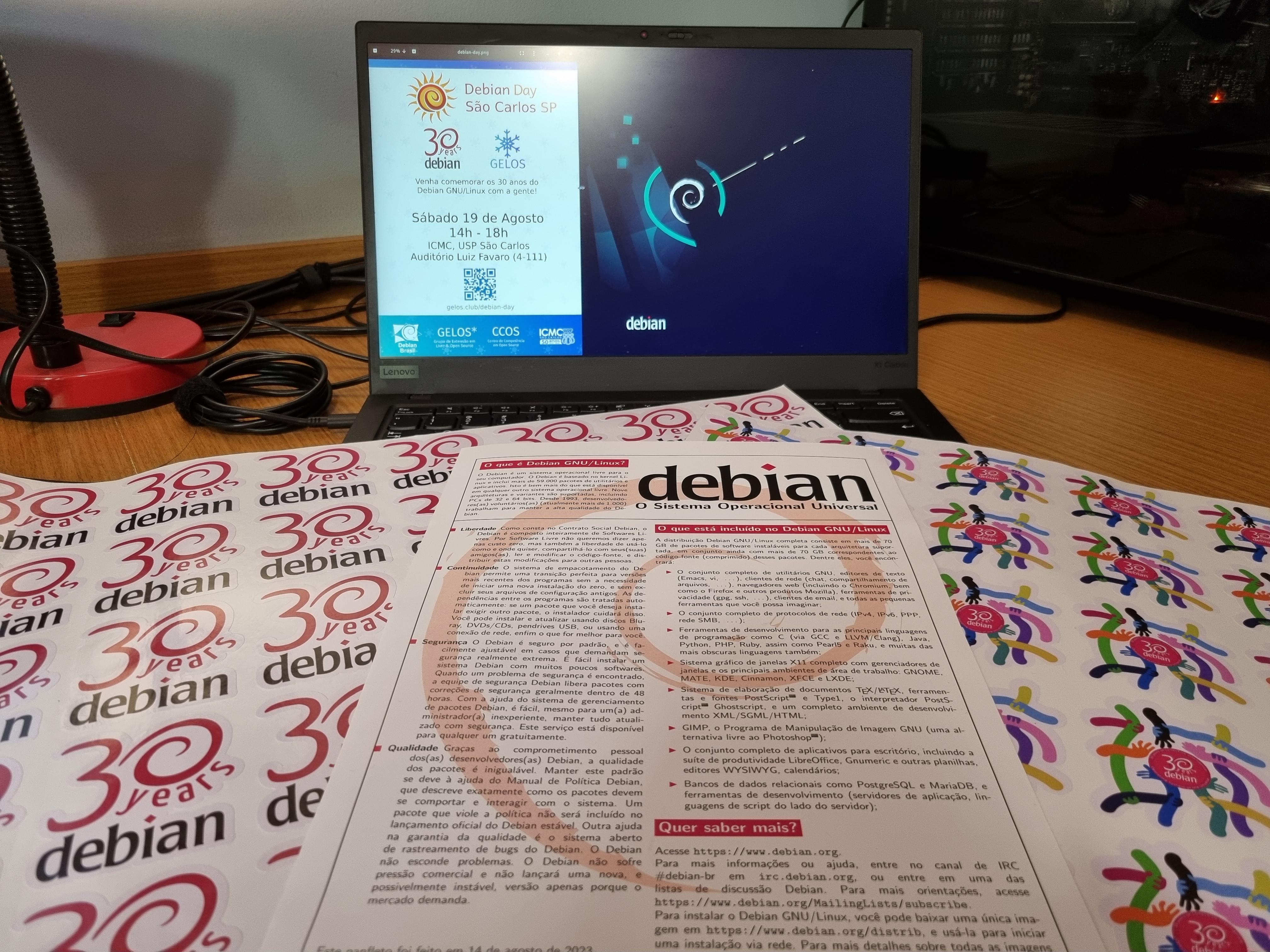



















 One of my earlier Slackware install disk sets, kept for nostalgic reasons.
One of my earlier Slackware install disk sets, kept for nostalgic reasons.





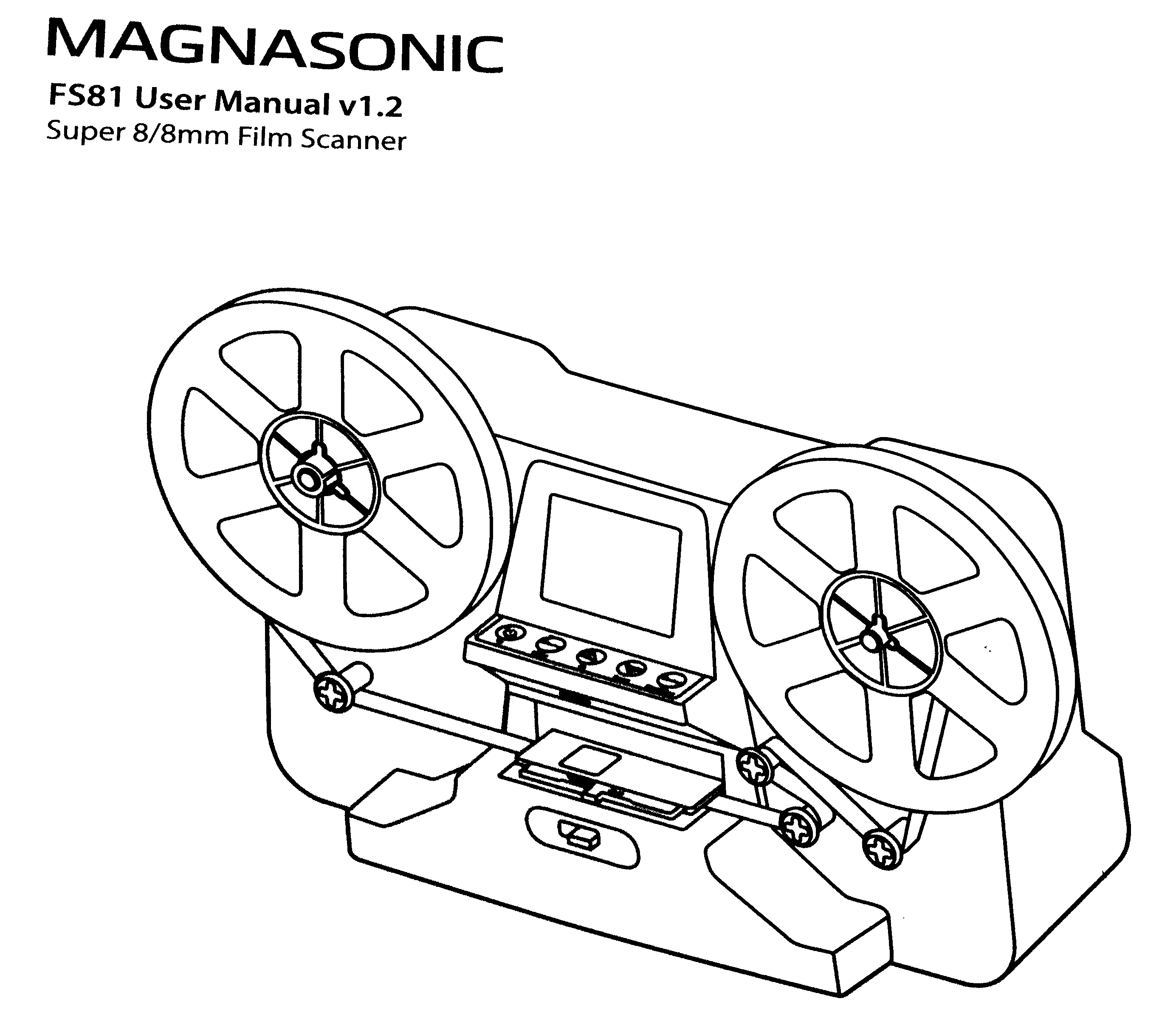
 After my father passed away, I brought home most of the personal items
he had, both at home and at his office. Among many, many (many, many,
many) other things, I brought two of his personal treasures: His photo
collection and a box with the 8mm movies he shot approximately between
1956 and 1989, when he was forced into modernity and got a portable
videocassette recorder.
I have talked with several friends, as I really want to get it all in
a digital format, and while I ve been making slow but steady advances
scanning the photo reels, I was particularly dismayed (even though it
was most expected most personal electronic devices aren t meant to
last over 50 years) to find out the 8mm projector was no longer in
working conditions; the lamp and the fans work, but the spindles won t
spin. Of course, it is quite likely it is easy to fix, but it is
beyond my tinkering abilities and finding photographic equipment
repair shops is no longer easy. Anyway, even if I got it fixed,
filming a movie from a screen, even with a decent camera, is a lousy
way to get it digitized.
But almost by mere chance, I got in contact with my cousin Daniel, ho
came to Mexico to visit his parents, and had precisely brought with
him a 8mm/Super8 movie scanner! It is a much simpler piece of
equipment than I had expected, and while it does present some minor
glitches (i.e. the vertical framing slightly loses alignment over the
course of a medium-length film scanning session, and no adjustment is
possible while the scan is ongoing), this is something
that can be decently fixed in post-processing, and a scanning session
can be split with no ill effects. Anyway, it is quite uncommon a
mid-length (5min) film can be done without interrupting i.e. to join a
splice, mostly given my father didn t just film, but also edited a lot
(this is, it s not just family pictures, but all different kinds of
fiction and documentary work he did).
After my father passed away, I brought home most of the personal items
he had, both at home and at his office. Among many, many (many, many,
many) other things, I brought two of his personal treasures: His photo
collection and a box with the 8mm movies he shot approximately between
1956 and 1989, when he was forced into modernity and got a portable
videocassette recorder.
I have talked with several friends, as I really want to get it all in
a digital format, and while I ve been making slow but steady advances
scanning the photo reels, I was particularly dismayed (even though it
was most expected most personal electronic devices aren t meant to
last over 50 years) to find out the 8mm projector was no longer in
working conditions; the lamp and the fans work, but the spindles won t
spin. Of course, it is quite likely it is easy to fix, but it is
beyond my tinkering abilities and finding photographic equipment
repair shops is no longer easy. Anyway, even if I got it fixed,
filming a movie from a screen, even with a decent camera, is a lousy
way to get it digitized.
But almost by mere chance, I got in contact with my cousin Daniel, ho
came to Mexico to visit his parents, and had precisely brought with
him a 8mm/Super8 movie scanner! It is a much simpler piece of
equipment than I had expected, and while it does present some minor
glitches (i.e. the vertical framing slightly loses alignment over the
course of a medium-length film scanning session, and no adjustment is
possible while the scan is ongoing), this is something
that can be decently fixed in post-processing, and a scanning session
can be split with no ill effects. Anyway, it is quite uncommon a
mid-length (5min) film can be done without interrupting i.e. to join a
splice, mostly given my father didn t just film, but also edited a lot
(this is, it s not just family pictures, but all different kinds of
fiction and documentary work he did).



 The more I say, the more depressed I will become so will leave it for now. In many ways the destruction seems similar to the destruction that
The more I say, the more depressed I will become so will leave it for now. In many ways the destruction seems similar to the destruction that  On etcd, performance and resource management
I attended a talk focused on etcd performance tuning that was very encouraging. They were basically talking
about the
On etcd, performance and resource management
I attended a talk focused on etcd performance tuning that was very encouraging. They were basically talking
about the  On jobs
I attended a couple of talks that were related to HPC/grid-like usages of Kubernetes. I was truly impressed
by some folks out there who were using Kubernetes Jobs on massive scales, such as to train machine learning
models and other fancy AI projects.
It is acknowledged in the community that the early implementation of things like Jobs and CronJobs had some
limitations that are now gone, or at least greatly improved. Some new functionalities have been added as
well. Indexed Jobs, for example, enables each Job to have a number (index) and process a chunk of a larger
batch of data based on that index. It would allow for full grid-like features like sequential (or again,
indexed) processing, coordination between Job and more graceful Job restarts. My first reaction was: Is that
something we would like to enable in
On jobs
I attended a couple of talks that were related to HPC/grid-like usages of Kubernetes. I was truly impressed
by some folks out there who were using Kubernetes Jobs on massive scales, such as to train machine learning
models and other fancy AI projects.
It is acknowledged in the community that the early implementation of things like Jobs and CronJobs had some
limitations that are now gone, or at least greatly improved. Some new functionalities have been added as
well. Indexed Jobs, for example, enables each Job to have a number (index) and process a chunk of a larger
batch of data based on that index. It would allow for full grid-like features like sequential (or again,
indexed) processing, coordination between Job and more graceful Job restarts. My first reaction was: Is that
something we would like to enable in {kind=link}